
Salesforce was down.
Okay, not all of Salesforce — but enough of it and for long enough that everyone at least heard about the great NA14 failure from friends or newsfeeds, if they hadn’t experienced it directly in their work.
Do you know what you would do if your SaaS product went down? Do you have any protocol or processes in place if technical disaster hit? Your business may not be so big as to worry about press write-ups or internet memes about a product failure — and your failure may not garner its own hashtag — but the situation can be just as much of a crisis for you and your customers.
Such a scenario affects almost every team at the company, some more than others. And when all various functional teams have to jump into action to address the same problem in different ways, it’s truly a test of organization, communication, and efficiency.
To help with this, here’s a quick game plan for each arm of the business, with some extra tips about how your business can handle failure aftermath and future prevention.
First things first
Ideally your dev team should notice any service disruptions before you hear from your customers. This requires you to have the right monitoring in place, but that’s not always the case, so…
When customers report a service issue, check your product on various devices, browsers, and connections before doing anything else. See if the issue is isolated, if it’s local rather than global. Then proceed accordingly.
Tips around communication
Proactive. Proactive. Proactive.
Communicate early and often with both your customers and your teammates.
Take ownership.
Admit the failure. Don’t try to explain it away or pass off responsibility. Don’t layer your message with glossy jargon or marketing speak. That’s just more irritating to your customers, and this is a crucial moment to maintain their trust.
Honest and transparent.
This doesn’t mean give every detail. It just means be clear about the situation — your product is not working — and share what you can about what you do and don’t know.
Stay consistent.
The best way to retain your customers’ trust throughout the resolution process is to provide a clear, consistent message. What you’re saying on Twitter should align with what Customer Success says on the phone. Otherwise you risk appearing disorganized (or incompetent) in the face of customers who are already questioning your product.
Don’t give false hopes.
It’s best not to provide precise ETAs for fixes to avoid setting false expectations and worsening the customer experience. Instead stick to what you reasonably expect, such as “in the next few hours” or “by the end of the day.”
Game plans
CEO
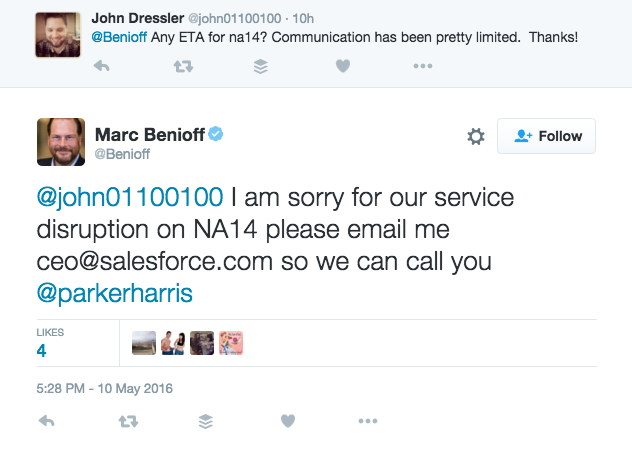
Speak up.
A personal apology from the CEO can go a long way with customers. After all, the CEO is the face of the business. Salesforce CEO Marc Benioff responded to countless tweets about the NA14 failure, looping in his cofounder Parker Harris as well.
Put someone in charge.
Assign someone to lead all internal management of the issue. Communication and coordination runs through this one person, keeping the resolution process streamlined and less chaotic.
Side-story: The “Incident Commander”

Hi, Ed here. Let me tell you about Incident Commanders.
An Incident Commander is traditionally a role which is assigned in an emergency response situation (e.g. fire, natural disaster) to coordinate all aspects of operations. See Wikipedia
At a company I used to work at, we adapted the role for emergency response to issues with our software platform – a platform that was mission-critical in nature, with any down-time causing significant economic loss to the business and clients.
As soon as a problem had been identified and raised as such, an incident commander was assigned from a pool of volunteers by the CTO. From this point, the person became responsible for:
- Documenting and reporting the problem accurately
- Acting as the central point of communication for all internal teams involved in the issue
- Giving updates to the management team on progress towards resolving the issue
- Recruiting any people required to work on the solution
Having this central role owning all communication meant that the people involved in fixing the problem could focus on doing just that – fixing the problem. It also sped up important decisions, particularly when teams who don’t traditionally communicate closely were required to collaborate.
Customer Success and Support
Be at the ready.
Stay available for incoming messages from customers, with a full understanding of the nature of the problem.
Constantly align with Dev.
There should be constant updates between CS and Dev, like a feedback loop. CS needs to let Dev know what customers are experiencing and observing, and Dev needs to provide CS with possible workarounds, updates, and any other information to relay to antsy customers.
Help customers through it.
Suggest other things the customer can do in the meantime. If there’s any part of the product that still offers value, remind the customer how they can use it.
Sales
If Sales reps rely on your live product during demos or scheduled calls with potential customers, they will need to postpone these.
The sales team should be kept informed, but otherwise doesn’t play much of a role in managing the situation.
Marketing
Take to social media.
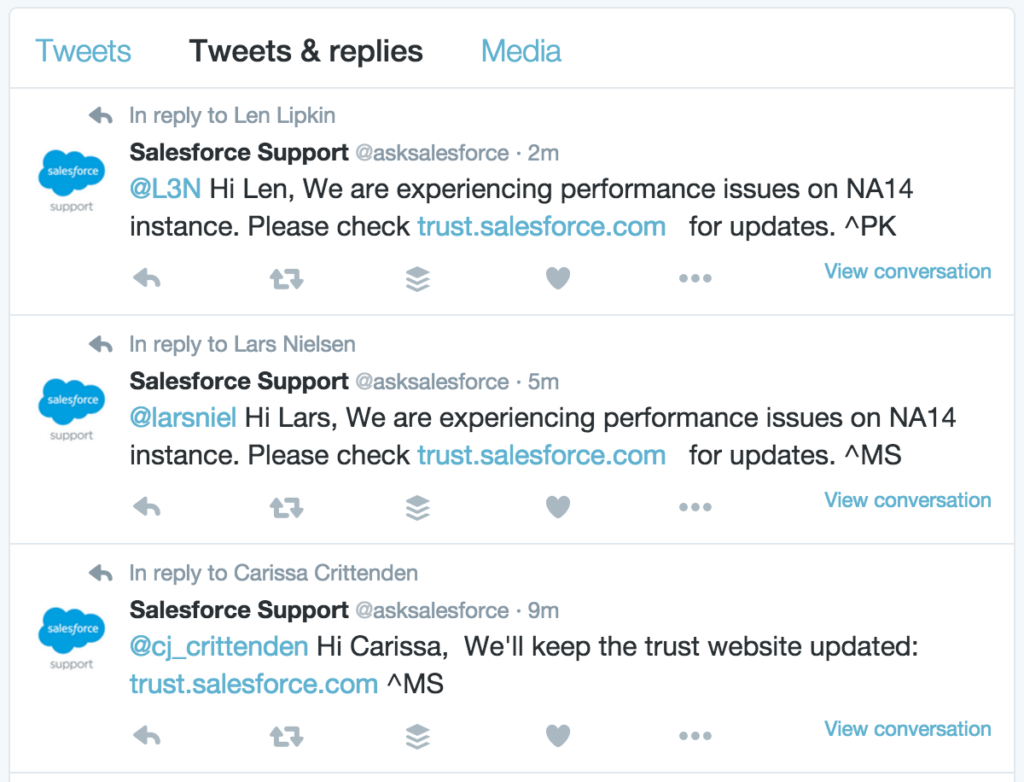
The marketing team should alert followers about the situation and also respond to every incoming message.
It’s probably better to use an “operations” Twitter to handle this, like we have at ChartMogul or like Salesforce has used throughout the NA14 crash. You don’t want to shout that your product is down — contain that message to your existing customers. Push it to another channel that’s more relevant, like this specific Twitter feed, and don’t interrupt your normal content.
Help customers through it.
Just like customer support, relay any workarounds available. Suggest other things the customer can do in the meantime. If there’s any part of the product that still offers value, remind the customer how they can use it.
Pause paid advertising.
If the failure persists, it may be worth considering pausing any paid campaigns that direct people to your product. For example if there’s an issue with your sign-up page, you might want to hold off any efforts that drive people to that page.
Product
Identify and prioritize a fix.
Determine the best course of action and coordinate with the engineering team to execute it. Do you want to run with a quick hot fix, or develop something longer term? Do you want to completely change a feature, or should you rollback a feature that you recently deployed?
Lead further investigation.
Assess the damage from the product failure. Was any data lost? If so, what and how much?
Engineering
The team’s mission here is pretty obvious. Conducting triage to find the problem, working with Product to classify and prioritize it, and then actually executing the solution.
The Aftermath
Follow up with customers.
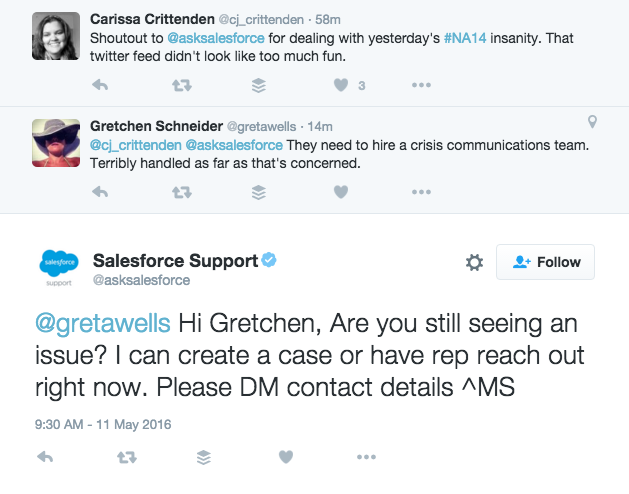
On both social media and with anyone who contacted the business via phone or email. Salesforce did a thorough job of this once NA14 was back up and running.
Salesforce attempted to satisfy some unhappy customers by following up with extra-mile customer service.
They even followed up with customers who did not even mention them directly but instead tweeted the hashtag, #NA14.
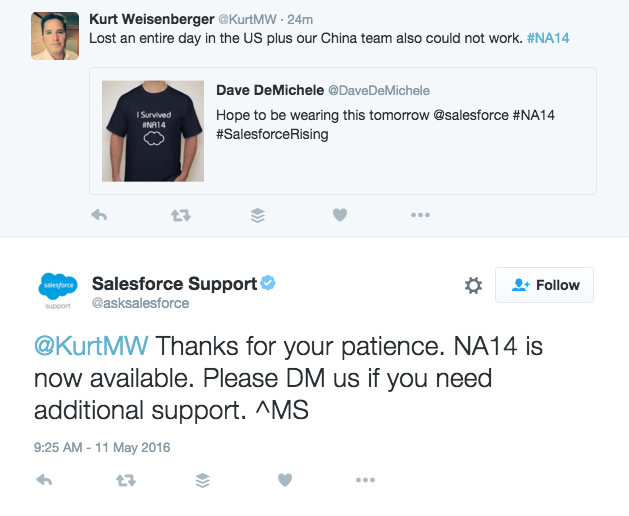
Figure out if there needs to be compensation.
This depends on the scenario and the damage caused, but might particularly come up in conversation if your company is B2B. Business customers have to deal with their own aftermath from any service interruptions their own customers experienced.
Share what you’ve learned.
Gather everyone who was involved with the service disruption to share what they learned from the experience. Come out with a clear set of actions that need to be taken to prevent it happening twice.
Prevention and Preparedness
Here are a few things you can put in place now:
1. Status page
Create a place on your site where people can check the service status of your product. First and foremost, a status page serves as a resource for customers. Your business appears professional and (at least somewhat) in control. Then, because customers can continuously check the site for updates instead of calling you, there is some relief for your customer support team.
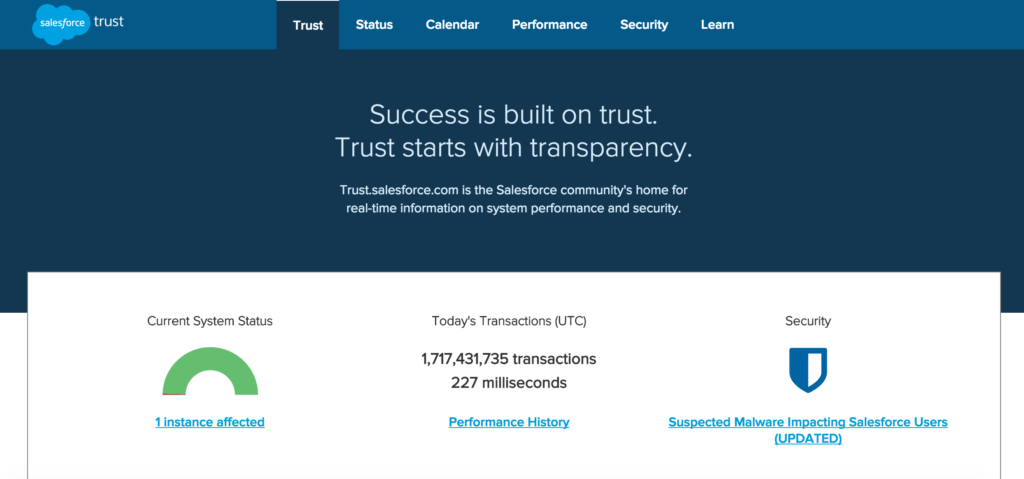
Salesforce continuously redirected customers to their status page, which is branded as “Salesforce Trust”.
It greets you with an overview of service and security.
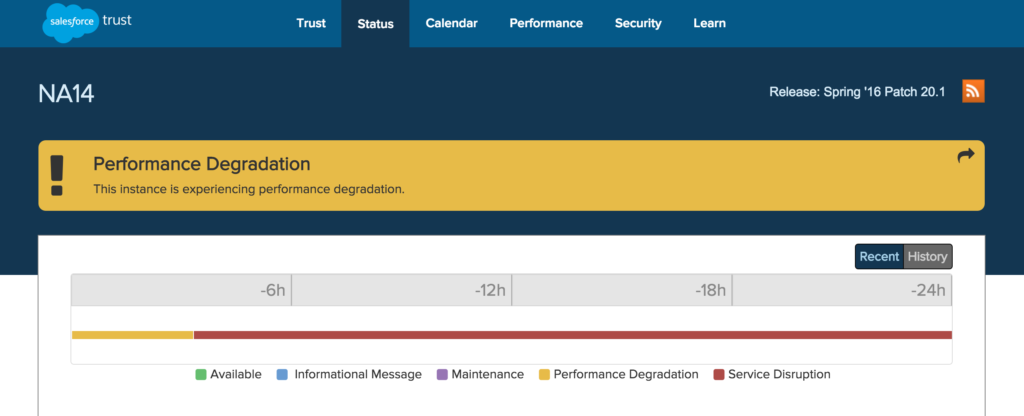
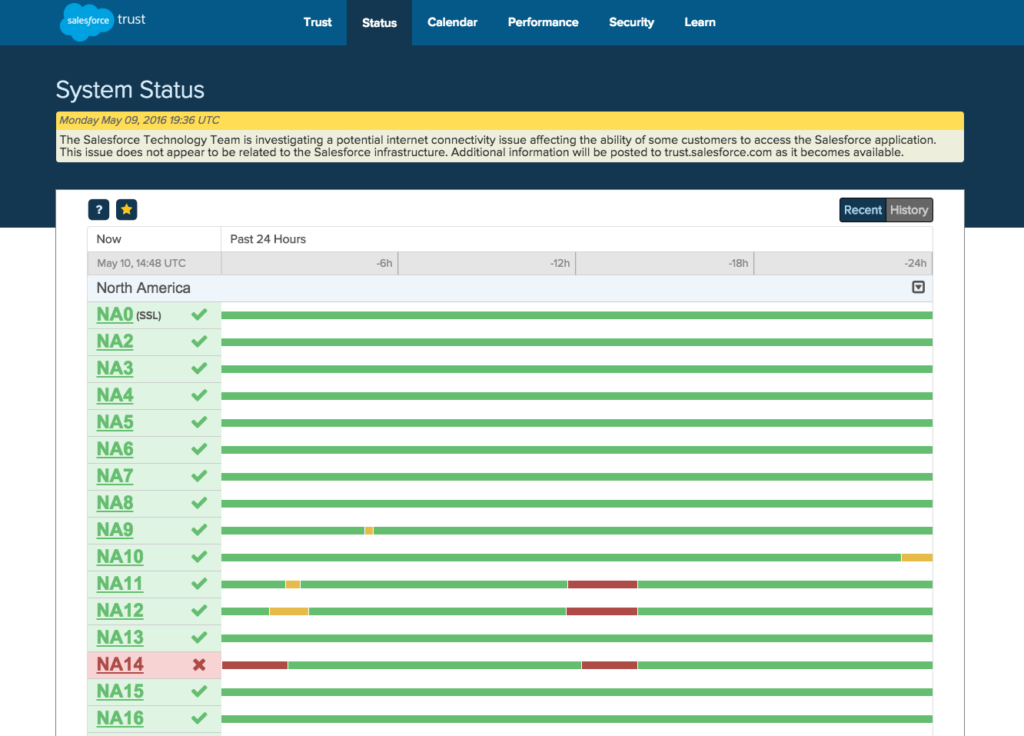
And the actual system status page provides a timeline bar of service updates, as well as a more technical breakdown of which exact segments are experiencing trouble.
2. Operations Twitter account
As mentioned above, an operations- or support-centric Twitter account can help you communicate during product emergencies. Let your customers know about this channel by advertising the handle in the following places:
- In the bio of your official Twitter account
- On your Support page
- As a footnote on Customer Support tickets or emails
- On your status page
3. A crisis manager, or your version of an Incident Commander
That’s the “disaster preparedness” plan we have to offer, inspired by the events at Salesforce. Have you been in this situation? Any tips or advice that we didn’t think of? Let us know in the comments!
Share and follow
NEW on @ChartMogul: What to do when your product is down — https://t.co/dodSlBk6Vx #NA14 #SaaS #SOS pic.twitter.com/a2Se1kYLUh
— ChartMogul (@ChartMogul) May 12, 2016